Built, not just proposed.
This is not a concept. A working prototype has been built and tested.
FLI is implemented as a working proof of concept. Every component of the architecture exists in code, produces traceable outputs, and is tested against realistic decision scenarios.
The principle is strict: decision logic lives in the ontology, not in application code. Every decision is traceable to exact inputs and conditions. Nothing is reconstructed after the fact.
Freelance UX designer. 3 years self-employed. Documented customer retainers. Application evaluated for a FlexiCard.
The document the system produces.
When a customer is rejected, FLI generates this compliance record automatically — at the moment of decision, from the same ontology that made it. No human drafts it. Nothing is reconstructed after the fact.
It satisfies EU AI Act Article 86(1) by construction: every condition tested, the exact threshold compared, the customer’s counter-evidence, and the OWL property linking their dispute to the specific decision node — all in one downloadable document. Unlike a PDF letter, the record is backed by OWL triples. A regulator can run a structured query across every decision in the portfolio — not read them one by one.
Not drafted by a compliance team after the fact. Produced by the pipeline at the moment of rejection.
The customer’s challenge is formally linked to the institution’s assessment node via challengesAssessment — not a separate complaint thread.
Backed by OWL triples, not readable text. A regulator can query across all decisions in the portfolio without reading each one.
Two ontologies — the institution’s domain ontology and the customer-side ontology — remain intentionally separate. Customer-side representation participates in the evaluation as a governed input. When the two diverge, the system does not silently decide. It surfaces the conflict as a typed governance signal.
The LLM explanation layer reads stored OWL facts — not a reconstructed narrative. The explanation is grounded in the same ontology that made the decision. It cannot confabulate.
From signal to review
FLI does not stop at detection. The governance dashboard below shows what happens next: once a divergence is classified, it enters a review workflow where the institution can intervene, refine ontology coverage, and adjust the policy logic that produced it.
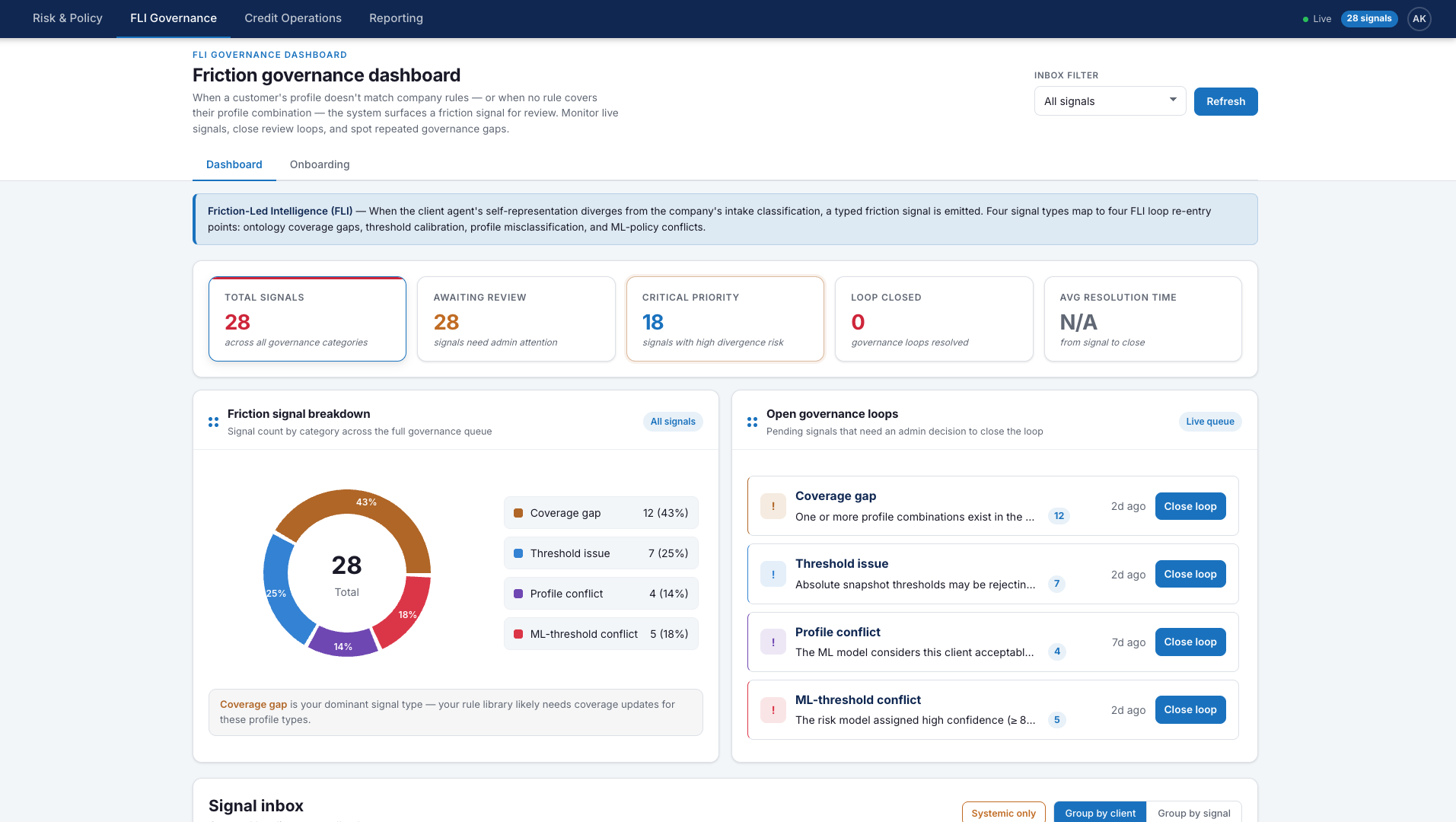
The customer profile falls outside rule coverage or conflicts with institutional classification.
The mismatch is recorded as a governance event: coverage gap, threshold issue, profile conflict, or ML-policy conflict.
The signal enters the admin queue, where governance can update ontology coverage, thresholds, or policy logic.